| Spark系统概述 |
为什么需要
和Hadoop有什么不同
Spark大数据处理框架
Spark基本功能
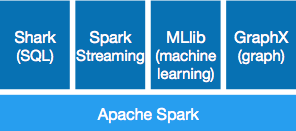
Spark基本组件
Spark计算模型
Spark 和Hadoop比较的差异和优点 |
| Spark
RDD及编程接口 |
Spark程序基本构成
Spark RDD
集合创建操作和存储创建操作
转换操作
控制操作(control operation)
行动操作(action operation) |
| Spark运行模式及原理 |
Spark运行模式列表
Spark基本工作流程
各种工作模式安装、部署、运行原理
Local运行模式
Standalone运行模式
Local cluster模式
Mesos模式
YARN standalone / YARN cluster模式
YARN client模式
各种模式的实现细节比较 |
Spark调度管理原理
|
Spark作业调度管理概述
Spark调度相关基本概念?
作业调度模块顶层逻辑概述
作业调度具体工作流程
任务集管理模块详解
调度池和调度模式分析
Spark应用之间的调度关系
调度过程中的数据本地性问题 |
| Spark的存储管理 |
存储管理模块整体架构
通信层架构
通信层消息传递
注册存储管理模块
存储层架构
数据块 (Block)
RDD 持久化
RDD分区和数据块的关系
内存缓存
磁盘缓存
持久化选项
如何选择不同的持久化选项
Shuffle数据持久化
广播(Broadcast)变量持久化 |
| Spark监控管理 |
UI管理
实时UI管理
历史UI管理
Metrics管理
Metrics系统架构
Metrics系统配置
输入源(Metrics Source)介绍
输出方式(Metrics Sink)介绍 |
| Shark架构与安装配置 |
Shark架构浅析
Hive/Shark各功能组件对比
MetaStore
CLI/ Beeline
JDBC/ODBC
Hive Server/2 与 Shark Server/2
Driver 145
SQL Parser 146
查询优化器(Query Optimizer)
物理计划与执行
Shark安装配置与使用
安装前准备工作
在不同运行模式下安装Shark
Shark SQL命令行工具(CLI)
使用Shark Shell命令
启动Shark Server
Shark Server2配置与启动
缓存数据表? |
| SQL程序扩展 |
程序扩展并行运行模式
Evaluator和ObjectInspector
自定义函数扩展
自定义数据存取格式
Spark SQL逻辑架构
Catalyst上下文(Context)
Java API
Python API
Spark SQL CLI
Thrift服务 |
| Spark
Streaming流数据处理框架 |
Spark
Streaming基本概念
性能调优
运行时间优化
内存使用优化
容错处理
DStream作业的产生和调度
DStream与RDD关系
数据接收原理
自定义数据输入源
自定义监控接口(StreamingListener)
Spark Streaming案例分析 |
| GraphX计算框架 |
图并行计算
数据并行与图并行计算
图并行计算框架简介
GraphX简介
GraphX模型设计
数据模型
图计算接口
GraphX模型实现
图的分布式存储
图操作执行策略
图操作执行优化
序列化和反序列化
GraphX内置算法库
GraphX应用
Pregel模型
N维邻接关系计算 |
| Tachyon存储系统 |
设计原理
框架设计
主节点
工作节点
客户端
读写工作流程
Tachyon的部署
单机部署
分布式部署
Tachyon的配置
Tachyon应用 |