| 培训模块 |
培训内容
|
| 第一部分: 数据分析基础—流程步骤篇 |
目的:掌握数据分析基本步骤和过程,学会如何构造数据分析框架
1、 数据决策的三个关键环节
• 业务数据化:将业务问题转化为数据问题
• 数据信息化:提取数据中的业务规律信息
• 信息策略化:基于规律形成业务应对策略
2、 数据分析的六步曲
• 步骤1:明确目的--理清思路
• 步骤2:数据收集—理清思路
• 步骤3:数据预处理—寻找答案
• 步骤4:数据分析--寻找答案
• 步骤5:数据展示--观点表达
• 步骤6:报表撰写--观点表达 |
第二部分: 数据分析框架—业务模型篇
|
1、 数据分析思路来源于业务模型
2、 分析框架来源于业务模型
• 商业目标(粗粒度)
• 分析维度/关键步骤
• 业务问题(细粒度)
• 涉及数据/关键指标
3、 常用的业务模型:PEST/5W2H/SWOT/PDCA/AARRR…
案例:搭建精准营销的分析框架(6R)
• 如何寻找目标客户群
• 如何匹配合适的产品
• 如何确定推荐的最佳时机
• 如何判断合理的价格
• ……
案例:搭建用户购买行为分析框架(5W2H) |
| 第三部分: 探索性分析法—统计分析篇 |
问题:数据分析方法的种类?分析方法的不同应用场景?
1、业务分析的三个阶段
• 现状分析:通过企业运营指标来发现规律及短板
• 原因分析:查找数据相关性,探寻目标影响因素
• 预测分析:合理配置资源,预判业务未来的趋势
2、常用的数据分析方法五大种类
3、统计分析基础(类别指标)
4、描述性分析法(现状分析)
• 对比分析(查看数据差距,发现事物变化)
演练:分析理财产品受欢迎情况及贡献大小
演练:用户消费水平差异分析,提取优质客户特征
• 分布分析(查看数据分布,探索业务层次)
案例:银行用户的消费层次/消费档次分析
演练:客户年龄分布/收入分布分析
• 结构分析(查看指标构成,评估结构合理性)
案例:收入结构分析/成本结构分析
案例:动态结构分析
• 趋势分析(查看变化趋势,了解季节周期性)
案例:营业厅客流量规律与排班
案例:用户活跃时间规律/产品销量的淡旺季分析
演练:产品订单的季节周期性规律
5、 相关性分析(原因分析)
• 相关分析(衡量两变量间的相关程度,三种相关系数)
• 方差分析(判断影响目标变量的关键要素,适用场景)
• 卡方检验(从多个维度的数据指标分析)
演练:不同客户的产品偏好分析
演练:银行用户违约的影响因素分析 |
| 第四部分: 用户风险识别—异常数据篇 |
1、 反欺诈识别的重点内容
• 如何识别异常数据
• 如何查找影响因素
• 如何提取欺诈用户的特征
• 如何预测用户的欺诈行为
2、 异常数据的定义
3、 异常数据的检测方法
• 基于统计法:标准差法、四分位距法、离群点检测算法
• 基于机器学习:回归、聚类等
4、 异常数据处理方法
• 演练:各种异常数据识别 |
| 第五部分: 影响因素分析—根因分析篇 |
问题:如何做原因分析?比如价格是否可用于产品销量?影响用户违约的关键因素是什么?
1、 数据预处理vs特征工程
2、 常用特征选择方法
• 相关分析、方差分析、卡方检验
3、 相关分析(衡量两数据型变量的线性相关性)
• 相关分析简介
• 相关分析的应用场景
• 相关分析的种类
• 简单相关分析
• 偏相关分析
• 距离相关分析
• 相关系数的三种计算公式
• Pearson相关系数
• Spearman相关系数
• Kendall相关系数
• 相关分析的假设检验
• 相关分析的四个基本步骤
演练:营销费用会影响销售额吗?影响程度如何量化?
演练:哪些因素与产品销量有显著的相关性
演练:影响用户消费水平的因素会有哪些
• 偏相关分析
• 偏相关原理:排除不可控因素后的两变量的相关性
• 偏相关系数的计算公式
• 偏相关分析的适用场景
4、 方差分析(衡量类别变量与数值变量间的相关性)
• 方差分析的应用场景
• 方差分析的三个种类
• 单因素方差分析
• 多因素方差分析
• 协方差分析
• 单因素方差分析的原理
• 方差分析的四个步骤
• 解读方差分析结果的两个要点
案例:摆放位置与销量有关吗
演练:客户学历对消费水平的影响分析
• 多因素方差分析原理
• 多因素方差分析的作用
• 多因素方差结果的解读
案例:广告形式、地区对销售额的影响因素分析
演练:销售员的性别、技能级别对销量有影响吗
• 协方差分析原理
• 协方差分析的适用场景
演练:排除用户收入,其余哪些因素对销量有显著影响?
5、 列联分析/卡方检验(两类别变量的相关性分析)
• 交叉表与列联表:计数值与期望值
• 卡方检验的原理
• 卡方检验的几个计算公式
• 列联表分析的适用场景
案例:产品类型对客户流失的影响分析
案例:用户学历对产品类型偏好的影响分析
研讨:行业/规模对风控的影响分析 |
| 第六部分: 数据建模过程—建模步骤篇
|
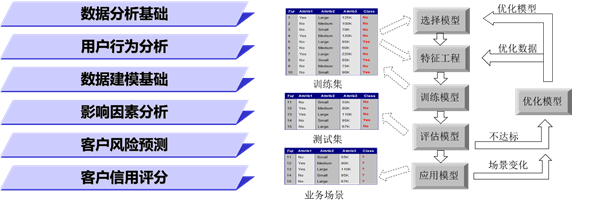
1、 预测建模六步法
• 选择模型:基于业务选择恰当的数据模型
• 特征工程:选择对目标变量有显著影响的属性来建模
• 训练模型:采用合适的算法对模型进行训练,寻找到最优参数
• 评估模型:进行评估模型的质量,判断模型是否可用
• 优化模型:如果评估结果不理想,则需要对模型进行优化
• 应用模型:如果评估结果满足要求,则可应用模型于业务场景
2、 数据挖掘常用的模型
• 定量预测模型:回归预测、时序预测等
• 定性预测模型:逻辑回归、决策树、神经网络、支持向量机等
• 市场细分:聚类、RFM、PCA等
• 产品推荐:关联分析、协同过滤等
• 产品优化:回归、随机效用等
• 产品定价:定价策略/最优定价等
3、 特征工程/特征选择/变量降维
• 基于变量本身特征
• 基于相关性判断
• 因子合并(PCA等)
• IV值筛选(评分卡使用)
• 基于信息增益判断(决策树使用)
4、 模型评估
• 模型质量评估指标:R^2、正确率/查全率/查准率/特异性等
• 预测值评估指标:MAD、MSE/RMSE、MAPE、概率等
• 模型评估方法:留出法、K拆交叉验证、自助法等
• 其它评估:过拟合评估、残差检验
5、 模型优化
• 优化模型:选择新模型/修改模型
• 优化数据:新增显著自变量
• 优化公式:采用新的计算公式
• 集成思想:Bagging/Boosting/Stacking
6、 常用预测模型介绍:回归、时序、分类 |
| 第七部分: 客户行为预测—分类模型篇 |
问题:如何评估客户购买产品的可能性?如何预测客户的购买行为?如何提取某类客户的典型特征?如何向客户精准推荐产品或业务?
1、 分类模型概述及其应用场景
2、 常见分类预测模型
3、 逻辑回归(LR)
• 逻辑回归的适用场景
• 逻辑回归的模型原理
• 逻辑回归分类的几何意义
• 逻辑回归的种类:二项、多项
• 如何解读逻辑回归方程
• 逻辑回归算法的实现及优化
✓ 迭代样本的随机选择
✓ 变化的学习率
✓ 逻辑回归+正则项
✓ 求解算法与惩罚项的互斥有关系
• 带分类自变量的逻辑回归分析
• 多项逻辑回归/多分类逻辑回归
✓ ovo, ovr
• 案例:用sklearn库实现银行贷款违约预测
• 案例:订阅者用户的典型特征(二元逻辑回归)
• 案例:通信套餐的用户画像(多元逻辑回归)
4、 分类决策树(DT)
问题:如何预测客户行为?如何识别潜在客户?
风控:如何识别欠贷者的特征,以及预测欠贷概率?
客户保有:如何识别流失客户特征,以及预测客户流失概率?
• 决策树分类简介
演练:识别银行欠货风险,提取欠贷者的特征
• 决策树分类的几何意义
• 决策树算法(三个关键问题)
✓ 如何选择最佳属性来构建节点:熵/基尼系数、信息增益
✓ 如何分裂变量:多元/二元划分、最优切割点
✓ 修剪决策树:剪枝原则、预剪枝与后剪枝
• 决策树的解读
• 决策树的超参优化
• 案例:商场用户的典型特征提取
• 案例:客户流失预警与客户挽留
• 案例:识别拖欠银行货款者的特征,避免不良货款
• 多分类决策树
• 案例:识别不同理财客户的典型特征,实现精准推荐
5、 人工神经网络(ANN)
• 神经网络的结构
• 神经网络基本原理
✓ 加法器,激活函数
• 神经网络分类的几何意义
• 神经网络的结构
✓ 隐藏层数量
✓ 神经元个数
• 神经网络实现算法
• 案例:评估银行用户拖欠货款的概率
6、 支持向量机(SVM)
• SVM基本原理
• 线性可分问题:最大边界超平面
• 线性不可分问题:特征空间的转换
• 维灾难与核函数 |
| 第八部分: 客户行为预测—模型评估篇 |
1、三个方面评估:指标、方法、过拟合
2、两大矩阵
• 混淆矩阵
• 代价矩阵
3、六大指标
• 正确率Accuracy
• 查准率Precision
• 查全率Recall
• 特异度Specify
• F度量值(/)
• 提升指标lift
4、三条曲线
• ROC曲线和AUC
• PR曲线和BEP
• KS曲线和KS值
5、多分类模型评估指标
• 宏指标:macro_P, macro_R
• 宏指标:micro_P, micro_R
6、模型评估方法
• 原始评估法
• 留出法(Hold-Out)
• 交叉验证法(k-fold cross validation)
• 自助采样法(Bootstrapping)
7、其它评估
• 过拟合评估:学习曲线
• 模型差异性评估
• 残差评估:白噪声评估 |
| 第九部分: 预测模型优化—超参优化篇 |
1、 模型优化的三大方向
• 超参优化
• 特征工程
• 集成优化
2、 超参优化的方法比较
• 交叉验证类(RidgeCV/LassoCV / LogisticRegressionCV/…)
• 网格搜索GridSearchCV
• 随机搜索RandomizedSearchCV
• 贝叶斯搜索BayesSearchCV
3、 超参调优策略 |
| 第十部分: 预测模型优化—特征工程篇 |
1、 数据清洗技巧
• 异常数据的处理方式
• 缺失值的填充方式
• 不同填充方式对模型效果的影响
2、 降维的两大方式:特征选择和因子合并
3、 特征选择的模式
• 基于变量本身的重要性筛选
• Filter式(特征选择与模型分离)
• Wrapper式(利用模型结果进行特征选择)
• Embedded式(模型自带特征重要性评估)
• 确定特征选择的变量个数
• 案例:客户流失预测的特征选择
4、 因子合并(将多数变量合并成少数几个因子)
• 因子分析(FactorAnalysis):原理、适用场景、载荷矩阵
• 主成份分析PCA:原理、几何含义、扩展KernelCA/ICA/…
• 案例:汽车油效预测
5、 变量变换
• 为何需要变量变换
• 因变量变换对模型质量的影响
• 特征标准化:作用、不同模型对标准化的要求、不同标准化对模型的影响
• 其它变换:正态化、正则化等
6、 变量派生:基于业务经验的派生、多项式派生
7、 特征工程的管道实现
• 管道类Pipeline
• 列转换类ColumnTransformer
• 特征合并类FeatureUnion |
| 第十一部分: 预测模型优化—集成优化篇 |
1、 模型的优化思路
2、 集成算法基本原理
• 单独构建多个弱分类器
• 多个弱分类器组合投票,决定预测结果
3、 集成方法的种类:Bagging、Boosting、Stacking
4、 Bagging集成:随机森林RF
• 数据/属性重抽样
• 决策依据:少数服从多数
5、 Boosting集成:AdaBoost模型
• 基于误分数据建模
• 样本选择权重更新公式
• 决策依据:加权投票
6、 高级模型介绍与实现
• GBDT梯度提升决策树
• XGBoost
• LightGBM |
| 第十二部分: XGBoost模型详解及优化 |
1、 基本参数配置
• 框架基本参数: n_estimators, objective
• 性能相关参数: learning_rate
• 模型复杂度参数:max_depth,min_child_weight,gamma
• 生长策略参数: grow_policy, tree_method, max_bin
• 随机性参数:subsample,colsample_bytree
• 正则项参数:reg_alpha,reg_lambda
• 样本不均衡参数: scale_pos_weight
2、 早期停止与基类个数优化(n_estimators、early_stopping_rounds)
3、 样本不平衡处理
• 欠抽样与过抽样
• scale_pos_weight= neg_num/pos_num
4、 XGBoost模型欠拟合优化措施
• 增维,派生新特征
✓ 非线性检验
✓ 相互作用检验
• 降噪,剔除噪声数据
✓ 剔除不显著影响因素
✓ 剔除预测离群值(仅回归)
✓ 多重共线性检验(仅回归)
• 变量变换
✓ 自变量标准化
✓ 残差项检验与因变量变换
• 增加树的深度与复杂度
✓ 增大max_depth
✓ 减小min_child_weight, gamma等
• 禁止正则项生效
5、 特征重要性评估与自动特征选择
6、 超参优化策略:
• 分组调参:参数分组分别调优
• 分层调参:先粗调再细调
7、 XGBoost模型过拟合优化措施
• 降维,减少特征数量
• 限制树的深度和复杂度
✓ 减小max_depth
✓ 增大min_child_weight,gamma等
• 采用dart模型来控制过拟合(引入dropout技术)
• 启用正则项惩罚:reg_alpha,reg_lambda等
• 启用随机采样:subsample,colsample_bytree等
8、 Stacking模式:XGBoost+LR、XGBoost+RF等
9、 XGBoost的优化模型:LightGBM |
| 第十三部分: 银行客户信用卡模型 |
1、 信用评分卡模型简介
2、 评分卡的关键问题
3、 信用评分卡建立过程
• 筛选重要属性
• 数据集转化
• 建立分类模型
• 计算属性分值
• 确定审批阈值
4、 筛选重要属性
• 属性分段
• 基本概念:WOE、IV
• 属性重要性评估
5、 数据集转化
• 连续属性最优分段
• 计算属性取值的WOE
6、 建立分类模型
• 训练逻辑回归模型
• 评估模型
• 得到字段系数
7、 计算属性分值
• 计算补偿与刻度值
• 计算各字段得分
• 生成评分卡
8、 确定审批阈值
• 画K-S曲线
• 计算K-S值
• 获取最优阈值
• 案例:构建银行小额贷款的用户信用模型 |
| 第十四部分: 数据建模实战篇 |
1、 电信业客户流失预警和客户挽留模型实战
2、 银行欠贷风险预测模型实战
3、 银行信用卡评分模型实战 |