|
|
|
|
|
|
|
|
全部课程 >大数据 |
|
Spark内存计算框架原理与实践应用
|
5740 次浏览  92 次 92 次
|
|
|
| 时间地点: 北京 上海 深圳根据报名开班 |
| 课程费用:5800元/人
|
|
|
|
| 企业内训:可以根据企业需求,定制内训,详见
内训学习手册 |
|
 |
认证方式:
培训前了解能力模型。
培训后进行能力评测:
在线考试
能力分析,给出学习建议
合格者颁发证书,作为职业技能资格证明
|
 |
|
|
Spark是成为替代MapReduce架构的大数据分析技术,Spark的大数据生态体系包括流处理、图技术、机器学习等各个方面,并且已经成为Apache顶级项目,可以预计的是2014年下半年到2015年在社区和商业应用上会有爆发式的增长。
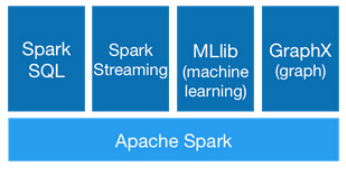
国内外一些大型互联网公司已经部署了Spark,并且它的高性能已经得到实践的证明。国外Yahoo已在多个项目中部署Spark,尤其在信息推荐的项目中得到深入的应用;国内的淘宝、爱奇异、优酷土豆、网易、baidu、腾讯等大型互联网企业已经将Spark应用于自己的生产系统中。国内外的应用开始越来越广泛。Spark正在逐渐走向成熟,并在这个领域扮演更加重要的角色。
在2014 Spark Summit上,世界20家顶级公司声明支持Spark,这些公司包括了最大的四个Hadoop发行商Cloudera,
Pivotal, MapR, Hortonworks,都提供了对非常强有力的支持Spark的支持:
本课程将首先介绍Spark的架构原理,然后结合实际项目案例讲解,如何根据需要对Spark进行应用设计、开发和运行优化。 |
| 培训目标: |
1、通过培训使学员深入理解Spark的大数据实现技术原理;
2、通过培训使学员深入理解并能运行Spark 的Core、Streaming、SQL、Mllib、GraphX等子项目;
3、通过培训使学员具备Spark内存计算框架的开发能力;
4、通过培训使学员学会Scala语言开发,以及开发Spark程序,处理业务数据; |
| 培训对象 |
| 1、大型网站、电商网站等运维人员;大数据开发工程师;2、熟悉Hadoop生态体系,想了解和学习Hadoop与Spark整合在企业应用实战案例的人员; |
| 学员基础:了解Hadoop基本框架,具有java编程基础 |
| 授课方式: 定制课程 + 案例讲解
+ 小组讨论,60%案例讲解,40%实践演练 |
| 培训内容:3天
|
| 大数据内存计算技术介绍(深入理解Spark
Core实现原理) |
1、Spark应用现状
2、Spark应用优势
3、Spark应用案例
4、Scala介绍
5、Mesos介绍
6、Spark介绍
7、Spark基本概念介绍
8、Spark架构剖析
9、Spark RDD计算模型解析
10、Spark RDD操作剖析
11、DAG有向无环图介绍
12、Spark编程
a)Java编写Spark程序
b)Scala编写Spark程序
c)Python编写Spark程序
d)R编写Spark程序
13、Spark可访问的数据源介绍
a)文件系统
b)HDFS
c)HBase
d)Hive
e)Cassandra
f)Tachyon
14、Spark编程技巧分享
15、Spark开发分析
16、Spark的执行机制解析
17、Spark运行原理剖析
18、Spark的调试与任务分配
19、Spark的性能调优
20、Spark与MapReduce对比分析
21、Spark生态体系剖析
22、Spark监控管理
23、Spark的容错机制剖析
24、Spark集群部署
25、Spark集群部署经验分享
26、Spark大规模集群运维经验分享
27、 Spark实战案例:Spark与HBase整合分析数据 |
| 大数据内存计算技术实战分享(深入理解Spark
Core使用实战操作) |
1、Spark Shell
2、PySpark
3、构建与运行Spark应用
4、Spark的性能调优
5、Spark实战案例:预测国际经济危机实战案例开发 |
| Shark数据仓库工具实战(深入理解Shark实现原理及开发实战) |
1、Spark
Shark概述
2、Hive与Shark
3、Spark Shark原理剖析
4、Spark Shark框架介绍
5、Spark Shark编程
6、Spark Shark分布式文件HDFS读写
7、Spark Shark APIs全面介绍
8、Shark UDFs
9、Shark UADFs
10、Shark HiveQL
11、Shark基于Spark的综合应用
12、Spark Shark实战案例:运营商话务数据分析案例剖析 |
| Spark
SQL技术实战(深入理解Spark SQL实现原理及开发实战) |
1、Spark
SQL概述
2、Spark SQL原理剖析
3、Spark SQL架构介绍
4、SparkSQL CLI
5、Tree和Rule
6、sqlContext和hiveContext的运行过程
7、Load/Save函数
8、Parquet文件读写
9、Spark SQL连接JDBC
10、Spark SQL连接ODBC
11、Spark SQL分布式文件HDFS读写
12、JSON数据集
13、Hive表
14、数据类型
15、Spark SQL与 Cassandra集成
16、Spark SQL APIs全面介绍
17、Spark SQL and DataFrames
18、Spark SQL and DataSets
19、Spark SQL HiveQL
20、Spark SQL编程
21、运行Spark SQL程序
22、在内存中缓存数据
23、Spark SQL UDFs
24、Spark SQL UADFs
25、Spark SQL SerDes
26、Spark SQL BI Tools
27、Spark SQL实战案例:数据分析案例剖析 |
| Spark
Streaming流计算技术实战(深入理解Spark Streaming实现原理及开发实战) |
1、Spark Streaming概述
2、Spark Streaming原理剖析
3、Spark Streaming流数据处理框架介绍
4、Spark Streaming编程剖析
5、初始化StreamingContext
6、Discretized Streams (DStreams)
7、输入DStreams与Receivers
8、基于DStreams的Transformations
9、基于DStreams的输出操作
10、Accumulators和Broadcast Variables
11、DataFrame和SQL操作
12、MLlib操作
13、Caching与Persistence
14、Checkpointing
15、运行Spark Streaming程序
16、性能调优:减少批处理时间
17、性能调优:设置正确的批处理间隔时间
18、内存调优
19、容错元语
实战案例:Spark Streaming与Kafka整合实现数据实时数据分析处理设计与分析 |
| Spark
GraphX图计算框架实战(深入理解Spark GraphX实现原理及开发实战) |
1、Spark GraphX概述
2、Spark GraphX图计算理论剖析
3、Spark GraphX框架剖析
4、Spark GraphX的图属性
5、Spark GraphX的图操作
6、操作列表
7、属性操作
8、结构操作
9、连接操作
10、近邻集合操作
11、Caching and Uncaching
12、Pregel APIs
13、Graph Builders
14、Vertex与Edge RDDs
15、Optimized Representation
16、Graph Algorithms
17、PageRank
18、Connected Components
19、Triangle Counting
20、Spark GraphX编程剖析
21、Spark GraphX APIs介绍
22、实战案例:Spark GraphX实现社交网络关系分析 |
spark
MLlib机器学习库实战(深入理解Spark MLlib实现原理及开发实战)
|
Spark MLlib概述
Spark MLlib算法库介绍
Spark MLlib架构剖析
Spark MLlib机器学习算法剖析
数据类型
基本统计算法
分类与回归
协同过滤
聚类
降维
特征提取与转换
频繁模式挖掘
评价指标
Spark MLlib编程
Spark MLlib APIs介绍
Spark MLlib机器学习算法应用实战
Spark MLlib实战案例:数据聚类分析案例剖析 |
| Spark集成R语言SparkR(R语言与大数据内存计算框架Spark集成) |
R语言概述
R语言语法介绍
R语言绘图函数
R语言高级绘图函数
SparkR集群部署
SparkR原理剖析
SparkR框架介绍
SparkR DataFrames
DataFrame的操作
选择行和列
Grouping和Aggregation
SparkContext和SQLContext
在SparkR中运行SQL查询
SparkR编程
在YARN上SparkR运行
SparkR机器学习
SparkR实战案例:运营商话务数据绘图 |
| 大数据推荐实战(深入理解大数据推荐技术以及推荐技术编程) |
1、个性化推荐的理论依据
2、个性化推荐的价值
3、个性化推荐能达到的目的
4、个性化推荐的原则
5、个性化推荐技术发展史
6、个性化推荐的相关技术
7、基于用户的常用推荐算法
8、基于用户的协同过滤推荐 |
|
|
|
|
|
| |
|
|
|
|
5740 次浏览 92 次
|
| 其他人还看了课程 |
|
|
|
|
|
| 咨询目标
|
对客户的数据库进行性能评价,设计优化,管理优化 |
| 咨询范围 |
数据库性能评价,数据库结构优化,数据访问SQL优化。 |
| 咨询方式 |
现有数据库调查,问题诊断,性能评价。
对数据库进行逻辑结构优化,对数据库进行访问SQL优化。
建立数据库运行监控平台。运行监控与优化方法指导。 |
| 成功案例 |
建设银行,中国农业银行,中国工商银行,中航信 |
| 详情咨询:010-62670969, zhgx@uml.net.cn
|
|
|
|
|
|
|






