求知
文章
文库
Lib
视频
iPerson
课程
认证
咨询
工具
讲座
Model Center
汽车系统工程
模型库
会员
找课
开班计划
|
认证培训
|
技术学院
|
管理学院
|
嵌入式学院
|
机械
|
军工学院
|
定向培养
|
专家指导
|
角色培养
电话
English
成功案例
品质保证
成功案例
某地铁控 大数据技术与实践
中航信 数据湖架构原理与应
某医疗磁 数据采集与处理
某科技公 大数据(Hadoo
诺基亚 Python基础
天津电子 Elasticse
中国电信 数据仓库与数据挖掘
更多...
相关课程
并发、大容量、高性能数据库
高级数据库架构设计师
Hadoop原理与实践
HBase原理与高级应用
Oracle 数据仓库
数据仓库和数据挖掘
Oracle数据库开发与管理
更多...
全部课程
>
大数据
Python数据建模(分类模型篇)
2076 次浏览
12 次
付老师
大数据专家,精通大数据分析与挖掘、机器学习技术。
地点时间:
北京、 上海、深圳根据报名开班
课程费用
:
4000元/人
报公开课
要内训
企业内训:
可以根据企业需求,定制内训,详见
内训学习手册
认证方式:
培训前了解能力模型。
培训后进行能力评测:
• 在线考试
• 能力分析,给出学习建议
合格者颁发证书,作为职业技能资格证明
本课程为高级课程《Python数据建模》的第三篇:分类篇
本课程主要讲解如何利用Python进行分类数据建模。
培训目标:
通过本课程的学习,达到如下目的:
1、 掌握数据建模的标准流程。
2、 掌握各种分类预测模型的原理,以及算法实现。
3、 掌握各种分类模型类的重要参数,以及应用。
4、 掌握模型的评估指标、评估方法,以及过拟合评估。
5、 掌握模型优化的基本方法,学会超参优化。
6、 掌握集成优化思想,掌握高级的分类模型。
培训对象:
业务支持部、IT系统部、大数据系统开发部、大数据分析中心、网络运维部等相关技术人员。
学员基础:
1.每个学员自备一台便携机 ( 必须 ) 。
2.便携机中事先安装好 Python 3.9 版本及以上。
3.安装好Numpy,Pandas,statsmodels,sklearn,scipy等常用库。
4.注:讲师现场提供分析的数据源。
授课方式:
建模流程+ 案例演练 + 开发实践 + 可视化呈现
采用互动式教学,围绕业务问题,展开数据分析过程,全过程演练操作,让学员在分析、分享、讲授、总结、自我实践过程中获得能力提升。
培训
内容:2天
培训模块
培训内容
第一部分: 预测建模基础
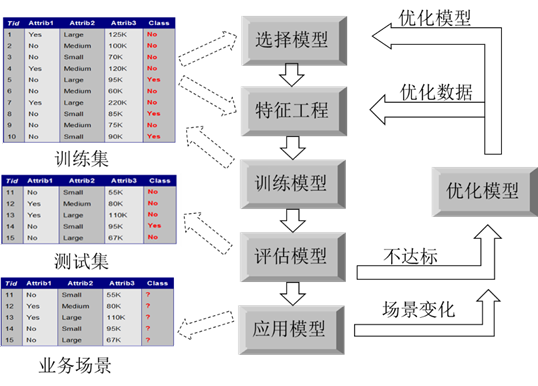
1、 数据建模六步法
• 选择模型:基于业务选择恰当的数据模型
• 属性筛选:选择对目标变量有显著影响的属性来建模
• 训练模型:采用合适的算法,寻找到最合适的模型参数
• 评估模型:进行评估模型的质量,判断模型是否可用
• 优化模型:如果评估结果不理想,则需要对模型进行优化
• 应用模型:如果评估结果满足要求,则可应用模型于业务场景
2、 数据挖掘常用的模型
• 数值预测模型:回归预测、时序预测等
• 分类预测模型:逻辑回归、决策树、神经网络、支持向量机等
• 市场细分:聚类、RFM、PCA等
• 产品推荐:关联分析、协同过滤等
• 产品优化:回归、随机效用等
• 产品定价:定价策略/最优定价等
3、 属性筛选/特征选择/变量降维
• 基于变量本身特征
• 基于相关性判断
• 因子合并(PCA等)
• IV值筛选(评分卡使用)
• 基于信息增益判断(决策树使用)
4、 训练模型及实现算法
• 模型原理
• 算法实现
5、 模型评估
• 评估指标
• 评估方法
• 过拟合评估
6、 模型优化
• 优化模型:选择新模型/修改模型
• 优化数据:新增显著自变量
• 优化公式:采用新的计算公式
7、 模型应用
• 模型解读
• 模型保存/加载
• 模型应用/预测
8、 好模型是优化出来的
第二部分: 分类模型评估
1、 三个方面评估:指标、方法、过拟合
2、 两大矩阵
• 混淆矩阵
• 代价矩阵
3、 六大指标
• 正确率Accuracy
• 查准率Precision
• 查全率Recall
• 特异度Specify
• F度量值(/)
• 提升指标lift
4、 三条曲线
• ROC曲线和AUC
• PR曲线和BEP
• KS曲线和KS值
5、 多分类模型评估指标
• 宏指标:macro_P, macro_R
• 宏指标:micro_P, micro_R
6、 模型评估方法
• 原始评估法
• 留出法(Hold-Out)
• 交叉验证法(k-fold cross validation)
• 自助采样法(Bootstrapping)
7、 其它评估
• 过拟合评估:学习曲线
• 残差评估:白噪声评估
第三部分: 逻辑回归
问题:如何评估客户购买产品的可能性?如何预测客户行为?
如何预测客户流失?银行如何实现欠贷风险控制?
1、 逻辑回归模型简介
2、 逻辑回归的种类
• 二项逻辑回归
• 多项逻辑回归
3、 逻辑回归方程解读
4、 带分类自变量的逻辑回归
5、 逻辑回归的算法实现及优化
• 迭代样本的随机选择
• 变化的学习率
6、 逻辑回归+正则项
7、 求解算法与惩罚项的互斥关系
8、 多元逻辑回归处理
• ovo
• ovr
9、 逻辑回归建模过程
案例:用sklearn库实现银行贷款违约预测
案例:订阅者用户的典型特征(二元逻辑回归)
案例:通信套餐的用户画像(多元逻辑回归)
第四部分: 决策树
1、 分类决策树简介
演练:识别银行欠货风险,提取欠贷者的特征
2、 决策树的三个关键问题
• 最优属性选择
• 熵、基尼系数
• 信息增益、信息增益率
• 属性最佳划分
• 多元划分与二元划分
• 连续变量最优划分
• 决策树修剪
• 剪枝原则
• 预剪枝与后剪枝
3、 构建决策树的算法
• C5.0、CHAID、CART、QUEST
• 各种算法的比较
4、 决策树的超参优化
5、 决策树的解读
6、 决策树建模过程
• 案例:商场酸奶购买用户特征提取
• 案例:客户流失预警与客户挽留
• 案例:识别拖欠银行货款者的特征,避免不良货款
• 案例:识别电信诈骗者嘴脸,让通信更安全
• 案例:电力窃漏用户自动识别
第五部分: 人工神经网络
1、 神经网络简介(ANN)
2、 神经元基本原理
• 加法器
• 激活函数
3、 神经网络的结构
• 隐藏层数量
• 神经元个数
4、 神经网络的建立步骤
5、 神经网络的关键问题
6、 BP算法实现
7、 MLP多层神经网络
• 案例:评估银行用户拖欠货款的概率
• 案例:神经网络预测产品销量
第六部分: 支持向量机(SVM)
1、 支持向量机简介
• 适用场景
2、 支持向量机原理
• 支持向量
• 最大边界超平面
3、 线性不可分处理
• 松弛系数
4、 非线性SVM分类
5、 常用核函数
• 线性核函数
• 多项式核
• 高斯RBF核
• 核函数的选择原则
第七部分: 模型集成优化篇
1、 模型的优化思想
2、 集成模型的框架
• Bagging
• Boosting
• Stacking
3、 集成算法的关键过程
• 弱分类器如何构建
• 组合策略:多个弱学习器如何形成强学习器
4、 Bagging集成算法
• 数据/属性重抽样
• 决策依据:少数服从多数
• 随机森林RandomForest
5、 Boosting集成算法
• 基于误分数据建模
• 样本选择权重更新
• 决策依据:加权投票
• AdaBoost模型
6、 GBDT模型
7、 XGBoost模型
8、 LightGBM模型
第八部分: 案例实战
1、 客户流失预测和客户挽留模型
2、 银行欠贷风险预测模型
结束:课程总结与问题答疑。
报公开课
要内训
2076 次浏览
12 次
其他人还看了课程
数据湖架构原理与应用
3916 次浏览
数据治理方法与实践
3694 次浏览
Scala编程语言
5073 次浏览
基于Hadoop大数据平台数据治理
6289 次浏览
大数据分析设计与建模
5650 次浏览
基于模型的数据治理与数据中台建设
15206 次浏览
大数据平台规划与设计-搜索与异地容灾
5691 次浏览
咨询服务:数据库设计与性能优化
咨询目标
对客户的数据库进行性能评价,设计优化,管理优化
咨询范围
数据库性能评价,数据库结构优化,数据访问SQL优化。
咨询方式
现有数据库调查,问题诊断,性能评价。
对数据库进行逻辑结构优化,对数据库进行访问SQL优化。
建立数据库运行监控平台。运行监控与优化方法指导。
成功案例
建设银行,中国农业银行,中国工商银行,中航信
详情咨询:010-62670969, zhgx@uml.net.cn
课程计划
UAF架构体系与实践 7-23[北京]
SysML和EA系统设计与建模 7-16[深圳]
Spec 驱动开发(SDD)实战 7-28[北京]
AI辅助软件测试方法与实践 7-31[在线]
AI智能体开发技术实践 8-6[上海]
基于UML和EA系统分析设计 8-20[上海]
 12 次
12 次