��֪
����
�Ŀ�
Lib
��Ƶ
Code
iProcess
�γ�
��֤
��ѯ
����
������
������
�ɳ�֮·
��Ա
�ҿ�
ȫ���γ�
|
����ѧԺ
|
����ѧԺ
|
Ƕ��ʽѧԺ
|
����ѧԺ
�ɹ�����
Ʒ�ʱ�֤
�绰
English
�漼������
��ʱ������
ÿ�쿴����
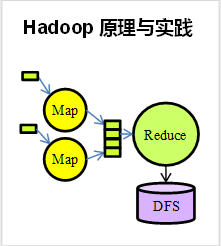
��ҵ��Hadoop�����ݴ������ʵ��
��������ʲô����һ����Ӫģʽ����һ������������һ�ּ���������һ�����ݼ��ϵ�ͳ�ƣ�����������˵�ġ������ݡ���ȥ��ͳ�����ϵġ����ݡ�������������������ݵ���Դ������Щ���ڴ����ݻ𱬵Ľ��죬��Щ���Ǵ�ͳ��ҵؽ����������⡣
�γ�ʵ¼
(ֻ������ѧԱ����)
��һ��
1.��Linux�IJ���ϵͳ
15:58
2.�����ݸ��������ݲֿ�
20.39
3.�ֲ�ʽ���ļ�ϵͳ�Ļ���˼��
24.01
4.MapReduce����ģ��
24.33
5.�����HBase�ı��ṹ
12.50
6.����Linux
09.21
�ڶ���
1.Hadoop��Ŀ¼�ṹ�ͱ���ģʽ�
23.18
2.�Hadoop��α�ֲ�ģʽ
21.22
3.�������¼��ԭ��������
17.43
4.�Hadoop��ȫ�ֲ�����
17.23
5.SecondaryNameNode������
10.09
6.Yarn�ĵ��ȹ��̺�HDFS�Ĺ���
29.06
������
1.MR֪ʶ��ع�
11.17
2.����WordCount���ݴ����Ĺ���
21.40
3.�����Լ���WordCount����
26.42
4.���л�
24.37
5. MR������
21.03
������
1.ʲô�Ƿ���
21.43
2.��������
17.18
3.ʲô��Combiner
09.46
4.ʲô��Shuffle
09.39
5.ʲô��Hive��Hive��ϵ�ܹ�
18.47
6.��װ����Hive
27.46
7.Hive���ڲ���.
20.09
8.Hive�ķ�����
20.24
������
1.Hive��Ͱ���ⲿ������ͼ
24.10
2.NoSQL����HBase����ϵ�ܹ�
15.14
3.�HBase����
14.31
4.ʲô��ZK��HA
15.43
5.������ƽ̨�ܹ�
23.36
�ɹ�����
��ҵ��Hadoop�����ݴ������ʵ��
��֤����
�й��ƶ���֤
���ܹ���ơ�
�й��ƶ���֤
���ܹ���ơ�
�й��ƶ���֤
������������
��������֤
���������ʦ��
˼����֤
���������ʦ��
����ͨ����֤
���������ʦ��